Monitoring for Kubernetes API server performance lags

What is the Kubernetes API server?
The Kubernetes API server is considered the core of the control plane. It acts as the main communication hub, processing and validating requests from users, controllers, and other Kubernetes components.
Whether you're deploying a new application, scaling workloads, or retrieving cluster metrics, all interactions go through the API server. It handles all the REST requests, validates configurations, and ensures that the cluster stays in sync.
What will happen if it fails?
If the API server slows down or crashes, the entire cluster management process is affected. Deployments can fail, workloads may be unresponsive, and troubleshooting can become a nightmare.
If the API server fails, here's what can happen:
- Deployments and scaling halt: The API server is responsible for handling deployment requests and scaling operations. Without it, new pods won't be scheduled, and existing workloads won't scale automatically.
- The cluster state becomes unreadable: Since all cluster state information flows through the API server, users and applications may not be able to retrieve current cluster details.
- Kubernetes controllers stop working: Controllers like the scheduler, node manager, and autoscaler rely on API server interactions. If it's down, these controllers can't function properly, leading to resource allocation issues.
- External integrations fail: Monitoring tools, logging systems, and external applications that interact with the API server will lose access, making it harder to detect and respond to issues.
These outcomes make API server stability a top priority for Kubernetes administrators. In the following sections, we'll explore how to identify and resolve performance issues to keep your cluster running smoothly.
Why does the Kubernetes API server slow down?
A sluggish API server is often the result of a few key issues. By identifying the root cause early, you can take steps to prevent outages and keep your cluster running smoothly.
- Too many requests: Controllers, operators, or external clients can flood the API server with requests, leading to bottlenecks.
- Authentication and authorization delays: If RBAC policies, webhook authentication, or API access requests are not optimized, they can slow things down.
- A lack of resources: If the API server doesn't have enough CPU, memory, or disk I/O capacity, response times will suffer.
- etcd performance issues: Since etcd stores all cluster state data, any slowdown in etcd directly impacts the API server.
- Network latency: Poor connectivity between the control plane and worker nodes can lead to API request delays.
- Admission controller overhead: When multiple validation and mutation webhooks run on every API request, response times can increase.
- Pod restarts and evictions: If the API server pod keeps crashing or being rescheduled, it will cause intermittent failures.
Steps to debug API server slowdowns
1. Track the API server metrics consistently
Keeping an eye on API server performance metrics is the first step in troubleshooting. Some key ones to track include the:
- Request latency (apiserver_request_duration_seconds ): Helps measure API server response times
- In-flight requests (apiserver_current_inflight_requests ): Depicts the number of ongoing requests
- etcd latency (etcd_request_duration_seconds ): Indicates how long etcd takes to process reads and writes
- Storage usage (apiserver_storage_objects ): Helps detect issues related to etcd storage capacity
- API requests by the status code (apiserver_request_total ): Helps identify the API requests that are unauthorized
Using a monitoring solution like Site24x7's Kubernetes monitoring , you can stay on top of API server performance by tracking key metrics in real time. The platform provides:
- Dashboards for visualizing the request latency, in-flight requests, etcd performance, and storage usage at a glance.
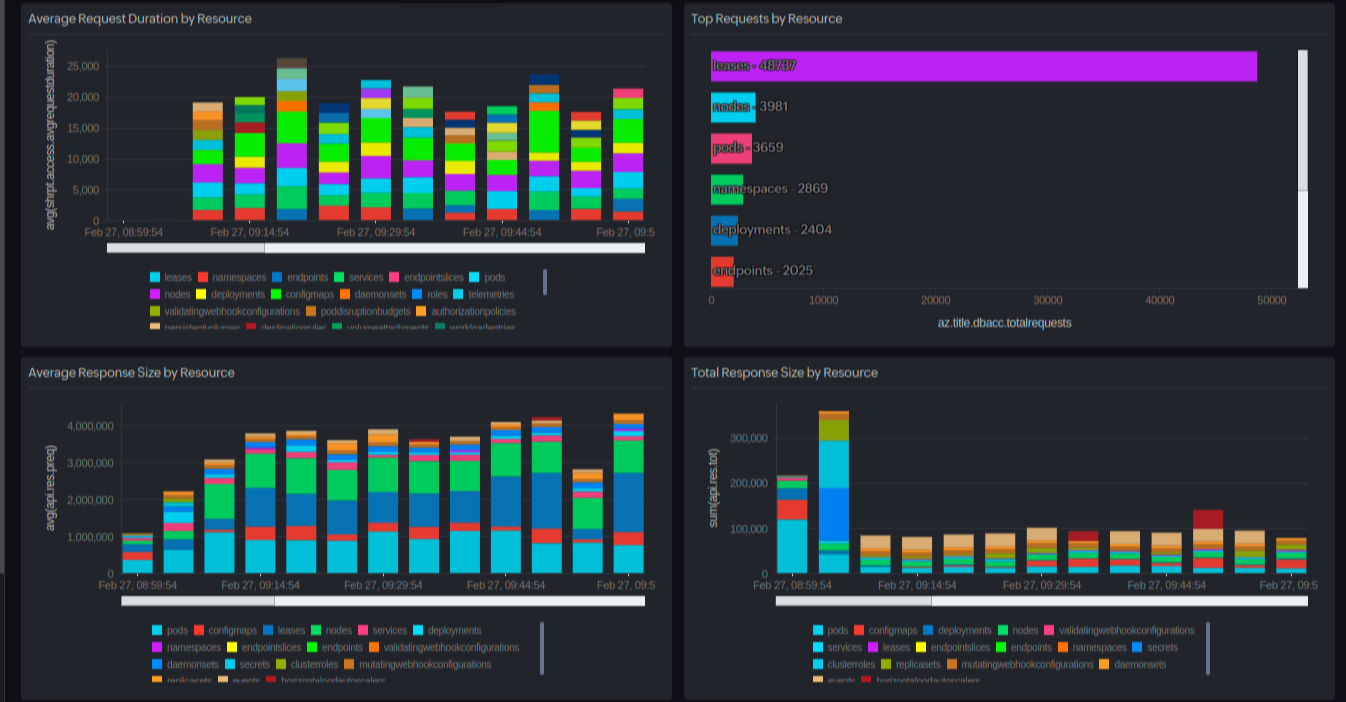
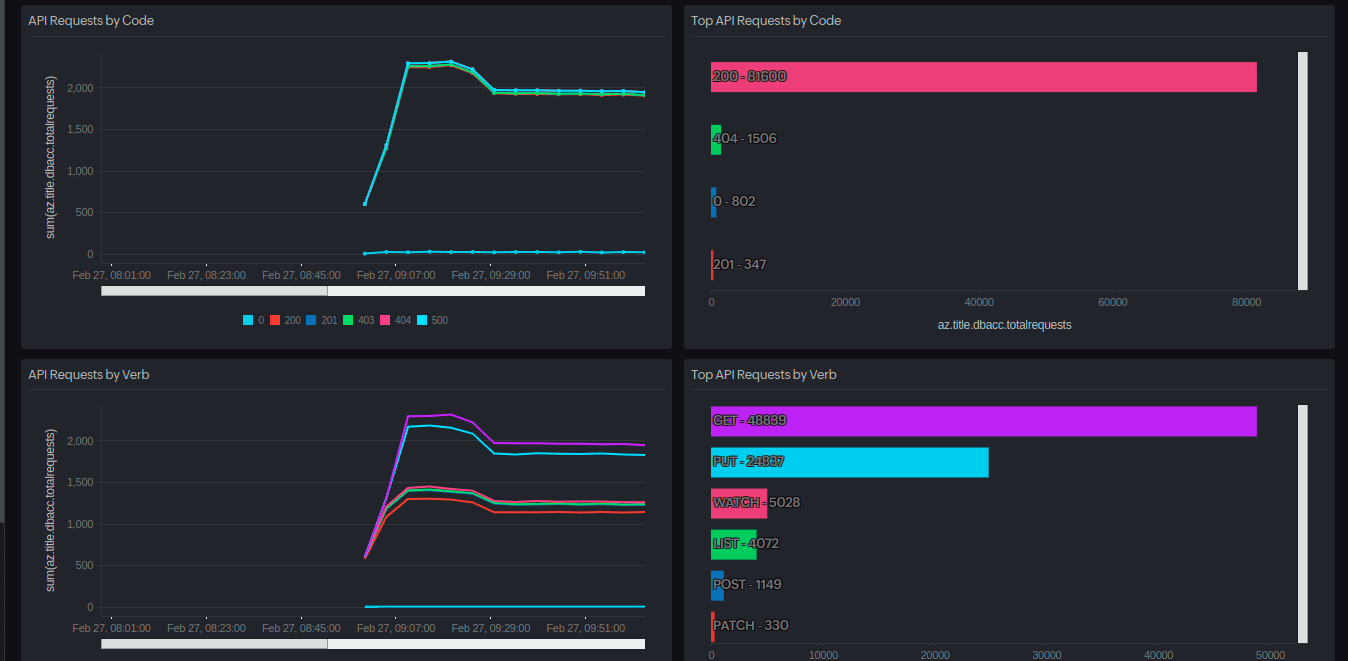
- Alerts that notify you of issues like high latency or storage limits before they become major problems.
- Drill-down insights to help you analyze unauthorized API requests and spot potential security concerns.
- Historical trends for identifying patterns and optimizing API server performance over time.
By keeping a close watch, you can troubleshoot issues faster and ensure a smoothly running Kubernetes control plane.
2. Reduce unnecessary API requests
If your organization is experiencing frequent API server slowdowns during traffic spikes, you need to figure out the issue as soon as possible. This might be because of an application frequently making unnecessary status queries. By implementing caching and optimizing request intervals, you can reduce the API load and improve cluster stability.
If the API server is overwhelmed, reducing the number of requests is a good place to start. To do so:
- Enable client-side caching and batch API requests to minimize redundant calls.
- Use API priority and fairness to balance request processing between workloads.
- Tune the --max-requests-inflight and --max-mutating-requests-inflight settings to better handle the API load.
3. Optimize etcd for faster data access
Since etcd underpins the API server, ensuring its efficiency is key.
- Scale etcd by adding nodes or increasing the available system resources.
- Run etcdctl defrag regularly to clean up storage and reduce fragmentation.
- Track etcd health with metrics like etcd_debugging_mvcc_db_total_size_in_bytes and etcd_server_leader_changes_seen_total .
4. Tune admission controllers
Admission controllers validate and mutate incoming API requests, but excessive webhook processing can slow things down.
- Identify slow webhooks with apiserver_admission_webhook_admission_duration_seconds .
- Use the built-in ValidatingAdmissionPolicy instead of external webhooks where possible.
- Optimize webhook configurations by reducing redundant checks and enabling response caching.
5. Fix network and connectivity issues
If your Kubernetes setup is experiencing random API failures, this might be because of heavy inter-service traffic congesting the control plane's network. By isolating API traffic onto a dedicated network interface, you can eliminate latency issues.
A slow or unstable network can contribute to API server lag. To optimize:
- Check the DNS resolution times and network policies for potential bottlenecks.
- Ensure stable connectivity between the API server and etcd .
- Use kubectl logs -n kube-system kube-apiserver-<node> to identify network-related errors.
6. Allocate sufficient resources to the API server
To keep the API server running smoothly:
- Ensure adequate CPU and memory capacity by setting appropriate resource requests and limits.
- Use a cluster autoscaler to dynamically adjust control plane resources.
- Move nonessential workloads off control plane nodes to free up resources.
Final thoughts
By now, you understand that a slow API server can cause serious disruptions. However, with proactive monitoring and optimization, you can keep your cluster responsive. Tools like Site24x7's Kubernetes monitoring solution make it easy to track performance, spot trends, and troubleshoot problems before they escalate. By optimizing request handling, tuning etcd , and ensuring sufficient resources are available, you can maintain a reliable, high-performing Kubernetes control plane.