Top 7 best practices for monitoring your OpenShift environment

Why should you monitor OpenShift?
- Deployment failures: Unmonitored deployment issues can halt operations.
- Performance bottlenecks: Problems may arise from CPU, memory, disk usage, network latency, or I/O bottlenecks.
- High CPU utilization: Overuse of CPU resources may hinder application deployment.
- Lost workloads: The dynamic changes that happen within workloads can cause tracking issues.
- Log management: Aggregating and analyzing logs from multiple sources can be challenging.
- Security: Ensuring security within OpenShift is complex but vital.
- Maintaining stability and efficiency: Regular tracking of resource consumption, application efficiency, and system well-being helps avoid interruptions.
- Faster troubleshooting: Quick identification and resolution of issues minimizes downtime and enhances user satisfaction.
- Optimized resource management: Ensuring resources are appropriately allocated prevents bottlenecks and improves performance.
Seven tips for a healthy OpenShift environment
To ensure your OpenShift environment is healthy and stable, consider these seven tips:
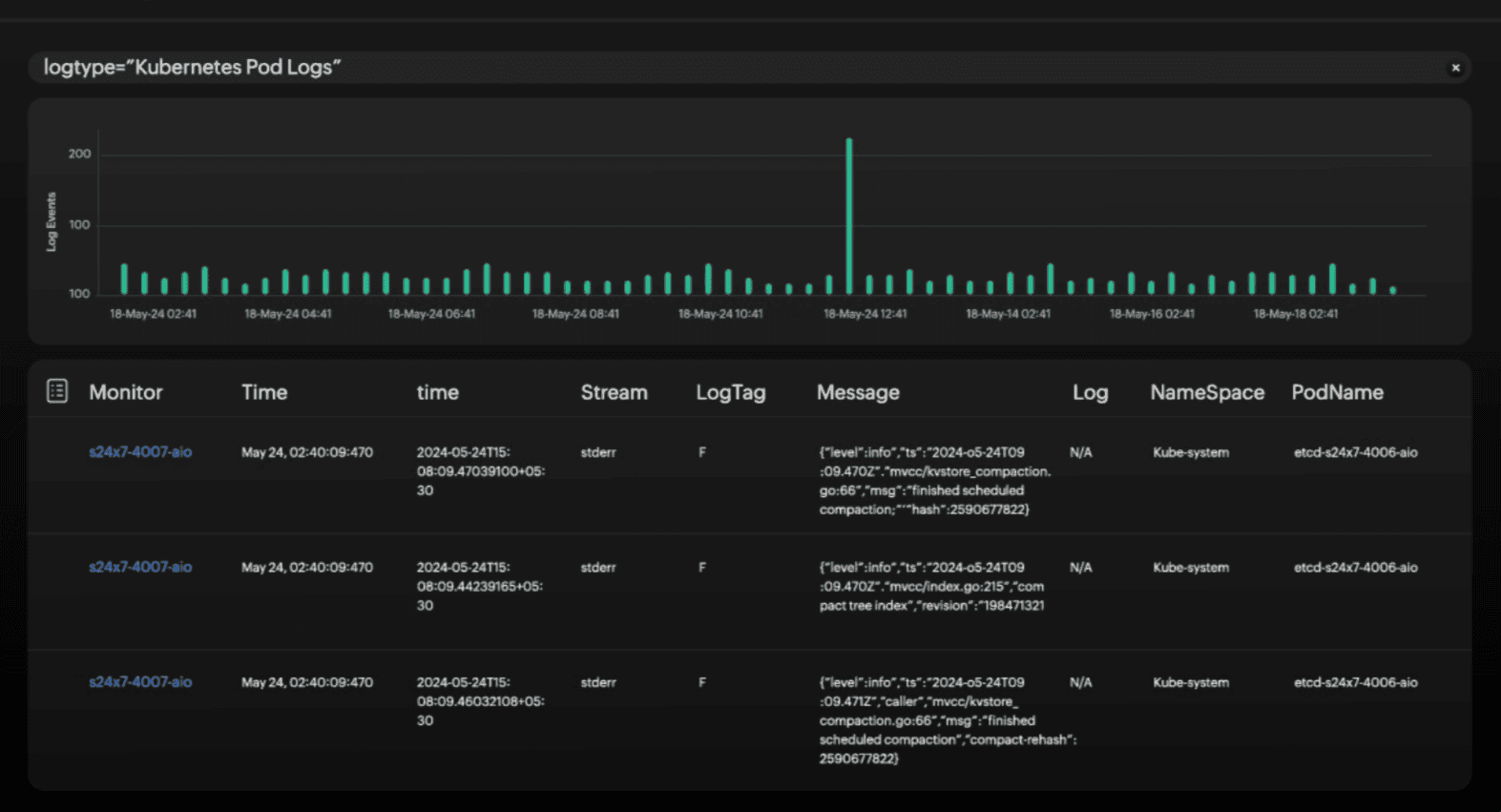
1. Observability
2. High availability
Ensure your OpenShift platform is available at all times. Your monitoring tool is invaluable during these periods. Utilize node redundancy, multiple pod replicas, and load balancing. Regularly back up your monitoring data and configurations, and adjust your monitoring setup to accommodate environmental changes. Make sure that the monitoring tool you employ is highly accessible. This is crucial to avert the possibility of losing sight of your workloads during disruptions.
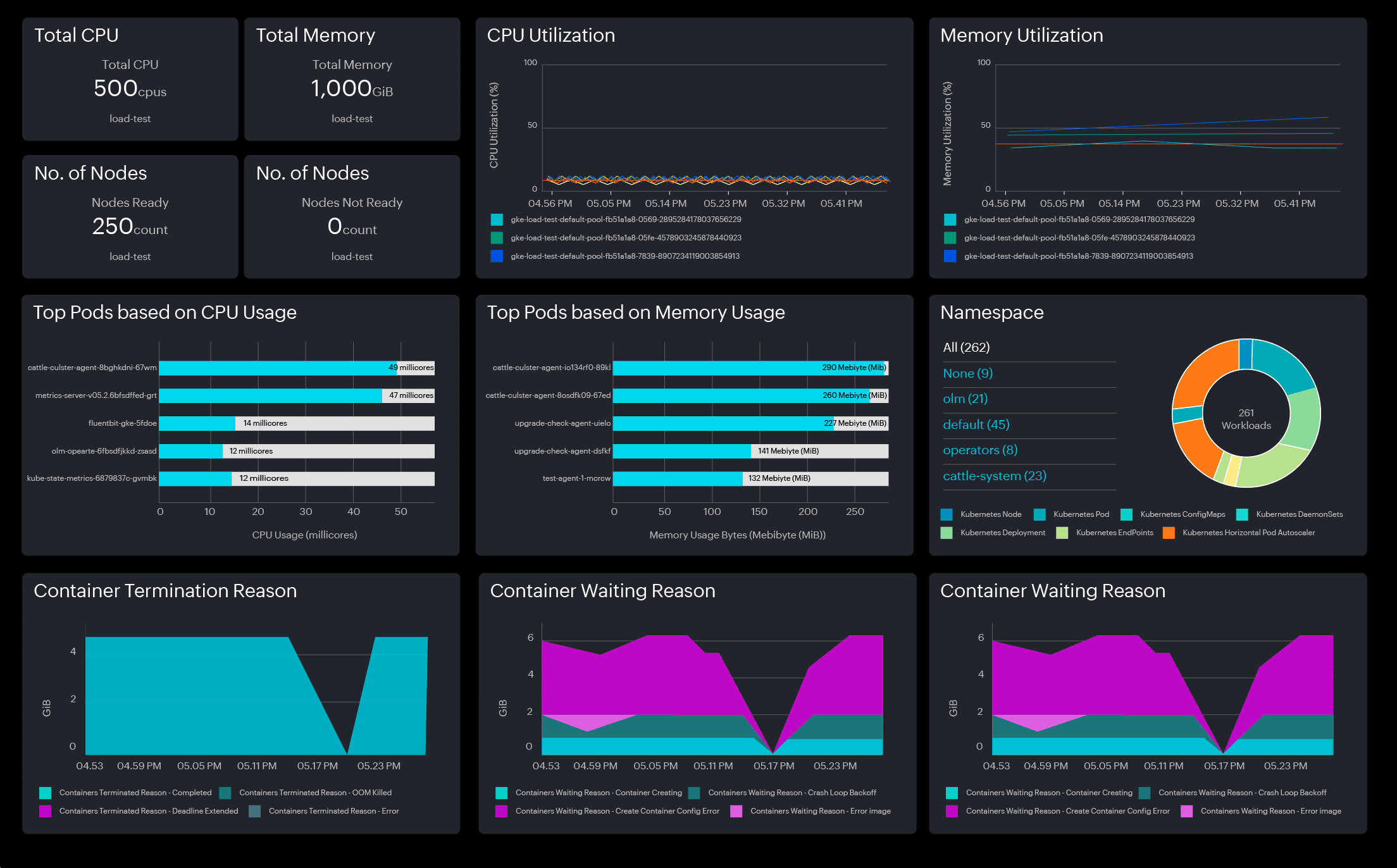
3. Critical metrics for resource utilization
Monitor critical metrics such as CPU and memory usage, disk capacity, and network statistics at the cluster, node, pod, namespace, and container levels and also at the individual workload levels. Understanding these metrics helps rectify discrepancies swiftly. Check out our whitepaper for more insights into the critical metrics to monitor in OpenShift.
4. Customized monitoring setup
Every organization has its own unique IT setup. Alter and repurpose the monitoring stack to fit your specific requirements. Create custom dashboards and reports to visualize critical components and set customized thresholds for alerts.
5. AIOps integration
Utilize AI intelligence to foresee resource consumption and adjust accordingly. Incorporating observability enhanced with AIOps facilitates the detection and analysis of problems promptly, offering a more comprehensive understanding of your environment.
6. Automate remedial actions
Set up automation rules for scenarios like traffic spikes to maintain performance. Automate recurring tasks and issue resolutions to ensure reliability and productivity. Use alerts to stay informed about potential issues.
7. Security
Implement security monitoring to track potential threats. Monitor system configurations, assign checks for various components, and follow guiding principles to ensure a secure platform.
Beyond basic monitoring
By adhering to these optimal practices, your OpenShift environment can achieve peak performance and availability, ensuring a smooth, efficient, and secure operational experience. For more comprehensive information on OpenShift monitoring and Observability, please refer to our whitepaper, A guide to monitoring OpenShift environments.