Surveiller les indicateurs du répartiteur de charge AWS
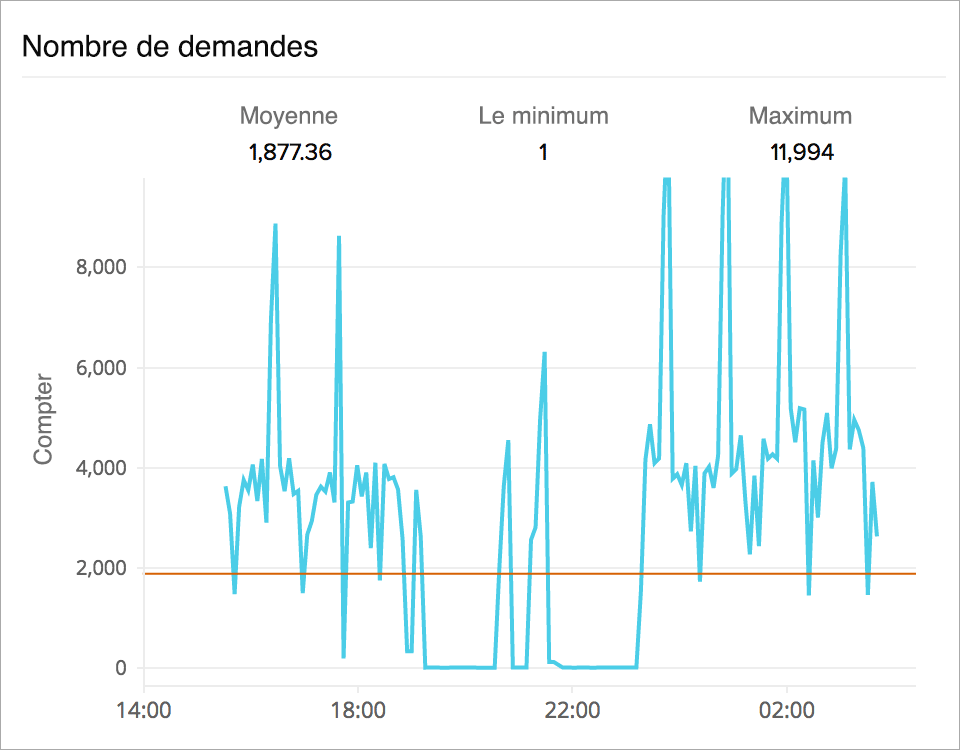
Analyser le nombre de demandes ELB
Suivez le nombre de demandes de clients reçues et acheminées par le répartiteur Elastic Load Balancer. La surveillance du taux de demande moyen vous donnera une idée de la demande de trafic pour votre application. L'analyse des tendances vous indiquera si vous devez ajouter des instances ou activer la mise à l'échelle automatique.
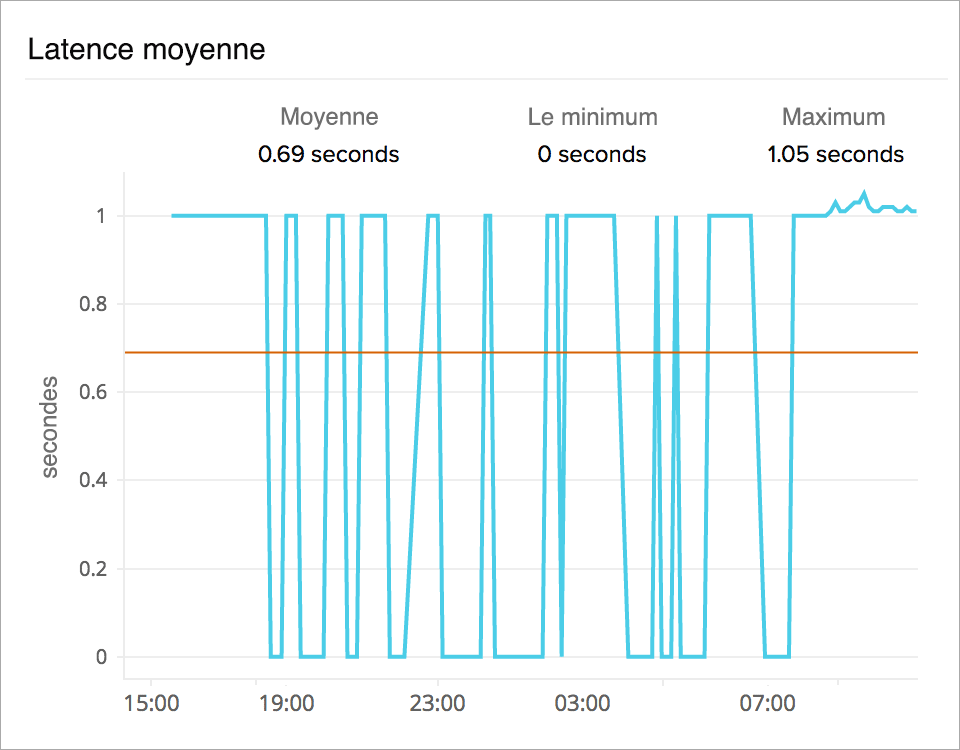
Identifier les modèles de latence
L'indicateur de la latence ou du temps de réponse cible vous donnera une idée du temps qu'il a fallu aux instances back-end pour répondre à la demande de l'application. Analysez l'utilisation des ressources des instances EC2 ou des conteneurs pour corréler les pics de latence avec l'augmentation de l'utilisation du processeur ou de la mémoire.
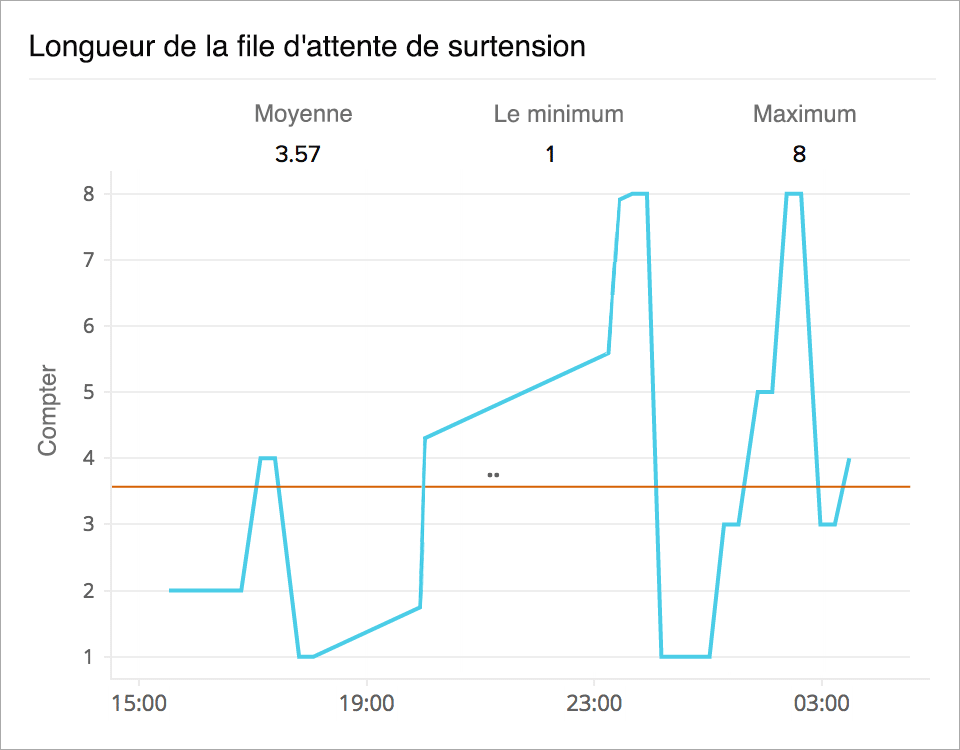
Éviter le débordement des demandes
L'augmentation de la latence et les contraintes liées aux ressources du système peuvent entraîner la mise en file d'attente des demandes. Suivez le nombre moyen de demandes mises en attente grâce à l'indicateur de la longueur de la file d'attente. Configurez des seuils et des alertes pour rester à l'affût de l'augmentation de la longueur de la file d'attente afin d'éviter le débordement des demandes.
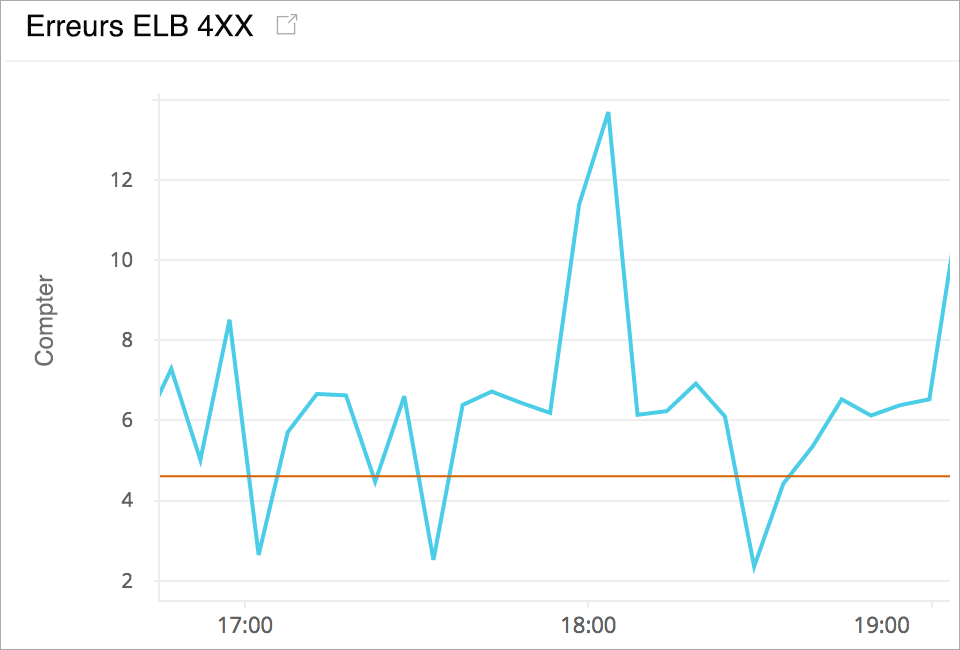
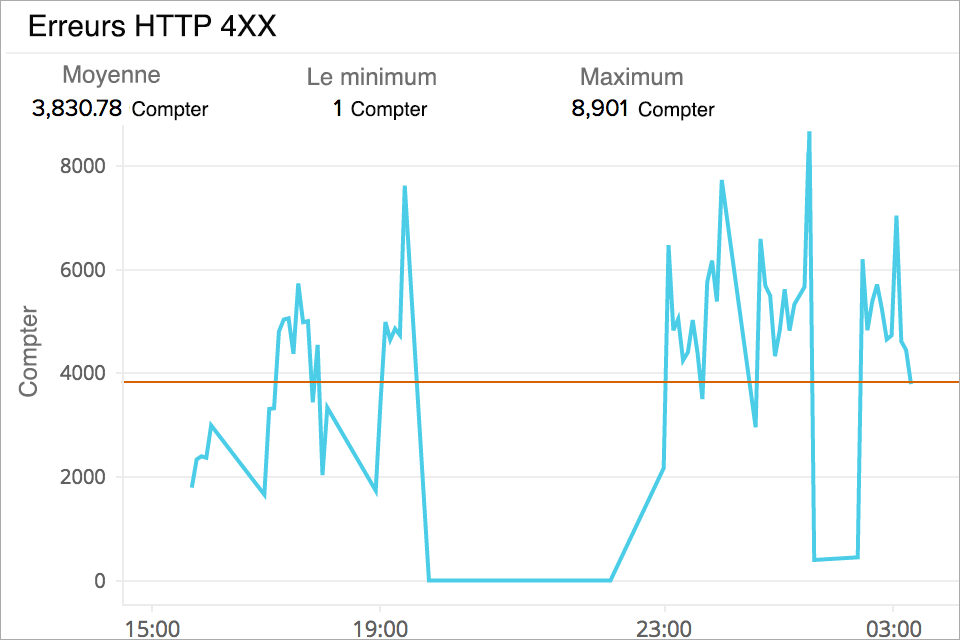
Dépanner les codes de réponse d'erreur HTTP ELB
Collectez des statistiques sur le nombre de codes de réponse d'erreur HTTP renvoyés par le répartiteur Elastic Load Balancer. Ces codes d'erreur peuvent être liés au client (erreurs 4XX) ou à l'instance dorsale (5XX). Identifiez les causes potentielles en analysant le type de code d'erreur renvoyé.
Surveiller les codes de réponse d'erreur HTTP cibles
Obtenez un agrégat des codes d'erreur HTTP 4XX et 5XX générés par les cibles de votre groupe. La surveillance et la mise en place d'alertes vous permettront de savoir quand vos serveurs back-end génèrent ces erreurs. Consultez vos journaux d'application pour connaître l'heure correspondante afin de résoudre le problème.
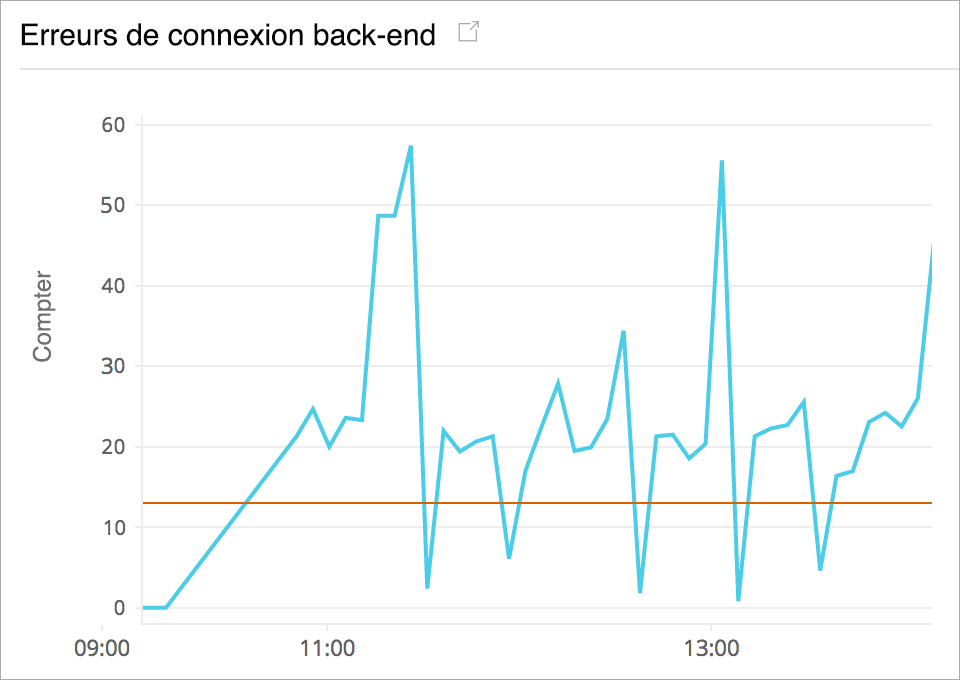
Corriger les erreurs de connexion au back-end
Mesurez le nombre de connexions qui n'ont pas pu être établies avec succès entre votre répartiteur de charge et ses instances enregistrées. Analysez en profondeur pour identifier si une instance EC2 particulière ou une zone de disponibilité est à l'origine du problème.
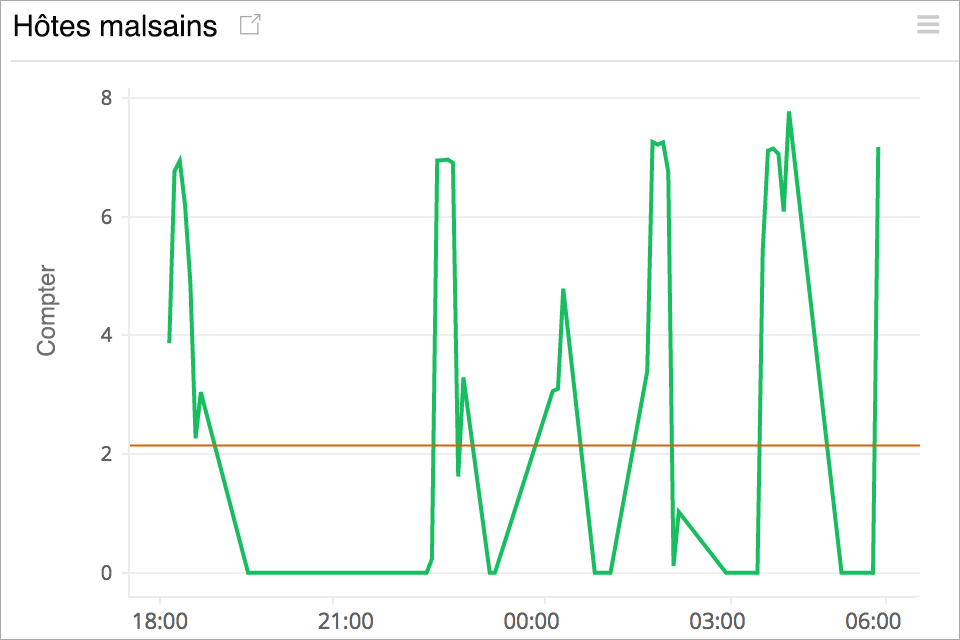
Suivi du nombre d'hôtes sains et malsains
Un nombre réduit d'hôtes sains enregistrés peut augmenter la latence à long terme. Surveillez le nombre moyen d'hôtes sains et non sains dans chaque zone de disponibilité et mettez en place des déclencheurs d'alerte pour vous assurer qu'il y a toujours suffisamment d'instances saines derrière votre répartiteur de charge pour répondre aux demandes entrantes.
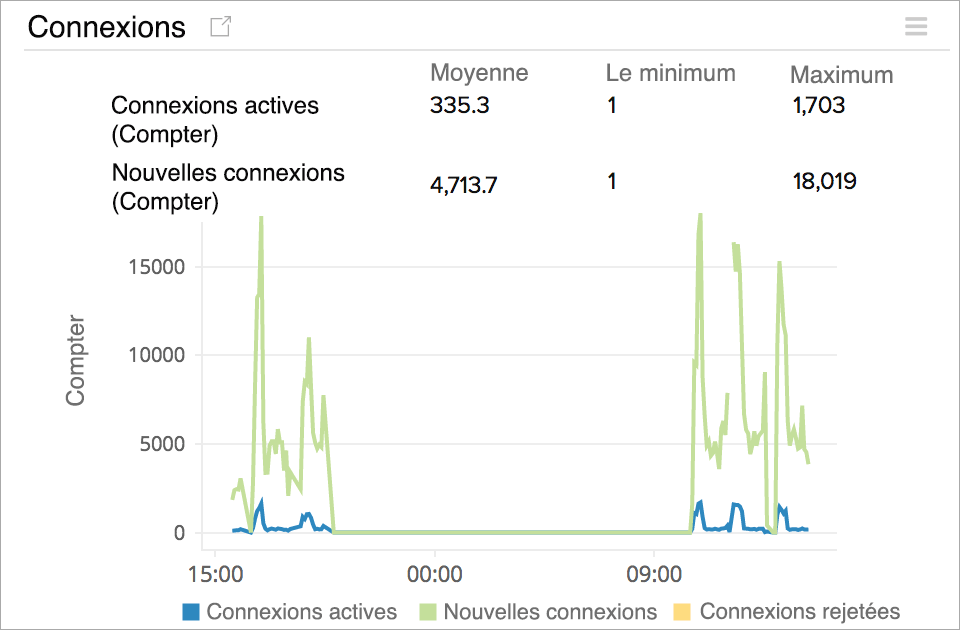
Vérifier les statistiques du nombre de connexions
Comprenez les statistiques de connexion front-end et back-end pour votre répartiteur Elastic Load Balancer de type Application. Suivez le nombre de connexions TCP nouvelles et actives établies entre le client, ELB et la cible. Comprenez l'évolutivité de votre système ELB et sachez combien de connexions de socket TCP concurrentes actives le répartiteur de charge peut gérer avant de commencer à les rejeter.
Effectuer la surveillance ELB AWS
Site24x7 offre une expérience globale de surveillance d'AWS avec le bon ensemble de fonctionnalités.
Journaux ELB à l'aide de la fonction Lambda
Découvrez comment collecter les journaux du répartiteur de charge des applications à l'aide de la fonction Lambda.
En savoir plusIndicateurs ELB AWS à surveiller
Blog sur les principaux indicateurs à surveiller pour AWS ELB.
En savoir plusMeilleures pratiques de surveillance
Découvrez comment gérer efficacement votre infrastructure AWS dans ce webinaire informatif.
